ほぼ関数だけでFizzBuzzしてツイートしたい【JavaScript】
2025/03/24目次
先日、SNSでFizzBuzzがはやっているのを見かけました。
弊社のコーディング規約で FizzBuzz を書ける人はおりまするか?🤔
— 悉生 游漩 (@StewEucen) March 15, 2025
<規約>
(1) else if を含む nested if 禁止
(2) switch 文禁止
(3) 三項演算子を if 文の制御構造の代わりに使うの禁止
(4) 以下の逐次処理禁止
- for
- while
- do-while
- for-in
- for-of
- Array#forEach#JavaScript
みなさんが実装された多種多様なFizzBuzzを読むのは面白いですし、時間差で追加の条件や仕様なども投稿されていて、実際のシステム開発みたいで興味深いなと感じました。
一方で私はそれらのコンテキストをあえて無視し、「使える言語機能が制限されているなら、ほぼ関数のみで実装したら最高では?1」と思ったので、ラムダ計算でFizzBuzzを実装することにしました。
リポジトリ:https://github.com/sititou70/lambda-fizz-buzz
レギュレーション
以下の言語機能のみを使用します。
- アロー関数、関数適用
- 文字列リテラル:
"Fizz"、"Buzz"、"FizzBuzz" - 数値リテラル:
0 - 数値演算:
+ 1 console.log
普通に実装する
まずは、よくあるラムダ計算の方法でFizzBuzzを実装します。
自然数を作る
チャーチ数を使って0、1、2を以下のように表現します。他の名前や予約語と衝突しないように、アンダースコアをつけています。
const _zero = (s) => (z) => z;
const _one = (s) => (z) => s(z);
const _two = (s) => (z) => s(s(z));チャーチ数は、sとzを受け取って、zにsを何回か適用した結果を返す関数です。ここで、sは次の数を返す関数(後者、successor)、zはゼロの気持ちです。
2を表す(s) => (z) => s(s(z))は、zをsに2回渡しているので、「『ゼロの次の数』の次の数」となって、2の意味になります。
toNumber
上記がわかると、チャーチ数をJavaScriptの数値に変換するtoNumberは、すぐに実装できます。
const _toNumber = (n) => n((x) => x + 1)(0);次の数
チャーチ数の次の数を返す関数succ、つまり、「チャーチ数を受け取って、次のチャーチ数を返す関数」も簡単に作れます。
const _succ = (n) => (s) => (z) => s(n(s)(z));チャーチ数nを受け取って、zにsを余分に1回多く適用しているだけです。
前の数
対して、チャーチ数の前の数を返す関数pred(前者、predecessor)の実装は難しいです。
少ない文字数での難しい定番の実装2があるのですが、私は自分で理解できるものしか書きたくないので、ここは長いけど簡単な方法で実装します。
ペア
まず、2つの値を保持できるペアを作ります。
const _cons = (car) => (cdr) => (selector) => selector(car)(cdr);
const _car = (pair) => pair((car) => () => car);
const _cdr = (pair) => pair(() => (cdr) => cdr);ペアは、「セレクタを受け取って、ペアのどちらかの値を返す関数」とします。
consはペアを生成します。ペアの最初の値carと、ペアの次の値cdrを受け取ると、「セレクタを受け取って、ペアのどちらかの値を返す関数」を返します。セレクタは、carとcdrの値を受け取ってどちらかを選択します。
carはペアを受け取ると、ペアの最初の値を返します。ペアにcarを選択するセレクタを渡しています。
cdrはペアを受け取ると、ペアの次の値を返します。ペアにcdrを選択するセレクタを渡しています。
ペアを使ったpredの実装
前者を求めたいチャーチ数nについて、zを(0, 0)、sを(pair) => (pair[0] + 1, pair[0])みたいにしてやります。
すると、ペアはsの適用のたびに以下のように変化していきます。
(0, 0)
(1, 0)
(2, 1)
(3, 2)
(4, 3)ペアによって常に1つ前の値を保持しているので、最終的にそれを取り出してやれば良いです。
したがって以下のように実装できます。
const _pred = (n) =>
// 最後にペアの次の数(cdr)を取り出す
_cdr(
// 前者を計算したいnに、
n(
// sを(pair) => (pair[0] + 1, pair[0])として、
(pair) => _cons(_succ(_car(pair)))(_car(pair))
)(
// zを(0, 0)として適用する
_cons(_zero)(_zero)
)
);初期値が(0, 0)なので、0の前者も0であることに注意です。
引き算
n1 - n2は、n1を「n2のs回」だけpredすれば良いので以下のようになります。
const _sub = (n1) => (n2) => n2(_pred)(n1);条件分岐
trueは、「trueとfalseそれぞれの値を受け取って、trueの値を返す関数」とします。falseはその逆です。
こうすると条件分岐は、真偽値にtrueとfalseのそれぞれの値を渡してやれば良いということになります。
// 真偽値がtrueかfalseかによって、どちらかの値に評価される
真偽値(trueの場合の値)(falseの場合の値)しかし、JavaScriptでは関数適用より先に引数の評価が行われる(値呼び、適用順序、作用的順序)ので、常に両方の値が評価されてしまいます。この後ループを使う予定で、それだとループがうまく停止しない場合があります。
なのでここでは、それぞれの値を関数でくるんで遅延(delay)することにします。具体的には以下のようにします。dtvalはdelayed true value、dfvalはdelayed false valueの気持ちです。
const _true = (dtval) => () => dtval();
const _false = () => (dfval) => dfval();
// 条件分岐は以下のように書ける
bool(() => trueの値)(() => falseの値);こうすると、trueの値やfalseの値が評価されるのは、dtval()やdfval()が評価されたときだけなので、boolの真偽に応じてどちらかだけ評価されるようになりました。
論理積
b1 && b2を計算するandは、以下のように実装できます。
const _and = (b1) => (b2) => b1(() => b2)(() => _false);b1がfalseの場合は、問答無用でfalseになります。b1がtrueの場合は、b2の真偽値をそのまま返します。
ゼロ判定
あるチャーチ数が0かどうかを判定します。
const _isZero = (n) => n(() => _false)(_true);zはtrueですが、1度でもsを適用するとfalseになっちゃうよ、という感じです。
比較
n1 < n2を比較するlessThanは、以下のようになります。
const _lessThan = (n1) => (n2) => _isZero(_sub(_succ(n1))(n2));これは、(n1 + 1) - n2 === 0の気持ちです。
0のpredが0だったことに注意してください。(n1 + 1) - n2の部分は0より小さくなりません。
あまりの計算
FizzBuzzで最も重要な、n1 % n2の計算は、以下のように実装できます。
// Zコンビネータ
const _fix = (g) => ((h) => g((n) => h(h)(n)))((h) => g((n) => h(h)(n)));
// n1 % n2の計算
const _mod = _fix(
// 自分自身であるmod
(mod) =>
// n1とn2をうけとって、
(n1) =>
(n2) =>
// n1 < n2を判定し、
_lessThan(n1)(n2)(
// n1 < n2の場合は、n1があまり
() => n1
)(
// n1 >= n2の場合は、(n1 - n2) % n2を計算する
// 自分自身であるmodを再帰的に呼び出す
() => mod(_sub(n1)(n2))(n2)
)
);n1 < n2になるまでn1からn2を引いていって、最後にn1をあまりとしています。
ループには、Zコンビネータを思いつきたいで求めたZコンビネータを使っています。
FizzBuzz関数
これまでの成果を使うと、FizzBuzz関数は以下のように実装できます。
const _fizzBuzz = (n) =>
(
(isMultOf3) => (isMultOf5) =>
_and(isMultOf3)(isMultOf5)(
// n % (3 * 5) === 0
() => "Fizz Buzz"
)(
// n % (3 * 5) !== 0
() =>
isMultOf3(
// n % 3 === 0
() => "Fizz"
)(
// n % 3 !== 0
() =>
isMultOf5(
// n % 5 === 0
() => "Buzz"
)(
// n % 5 !== 0
() => _toNumber(n)
)
)
)
)(
// n % _threeを計算してisMultOf3にわたす
_isZero(_mod(n)(_three))
)(
// n % _fiveを計算してisMultOf5にわたす
_isZero(_mod(n)(_five))
);ちょっと長いですが、これまでの議論を追っていると意外とわかりやすいです。
FizzBuzzのリストを表示する
指数
大きい数を効率的に生成するために指数を実装します。
の計算は、以下のようにシンプルに実装できます。
const _exp = (n1) => (n2) => n2(n1);これがなぜ指数の計算になるのかは、FizzBuzz関数の実装に関係ないので割愛しますが、動作を追いかけてみると楽しいのでおすすめです。
シーケンス
処理Aをしてから処理Bをするというシーケンスは、以下のように実装できます。
const _seq = (proc1) => (proc2) => proc2;
// proc1をしてからproc2をする。式はproc2に評価される。
_seq(proc1)(proc2);_seq(proc1)(proc2)を評価するとき、まず_seq(proc1)の部分を評価してからそれをproc2に適用することになります。なので、proc1が先に評価されてからproc2が評価されることになります。
256までのFizzBuzzを表示する
である256までのFizzBuzzをconsole.logで表示します。以下のようになります。
// 1からprintNumまでのFizzBuzzを表示する
const _printFizzBuzzList = (printNum) =>
printNum(
// printNumのsでは、
(n) =>
_seq(
// nのFizzBuzzを表示してから、
console.log(_fizzBuzz(n))
)(
// n + 1を返す。
_succ(n)
)
)(
// printNumのzは1
_one
);
// 4^4 = 256までのFizzBuzzを表示する
_printFizzBuzzList(_exp(_four)(_four));インラインに展開してみる
今回の実装では、変数はコードの読みやすさのためだけに使用していました。例えば、名前を使った再帰などをしていません。
なので、すべての変数をその中身に展開できます。見やすいように(?)適当な位置で改行しています。
// prettier-ignore
((printNum)=>printNum((n)=>((proc1)=>(proc2)=>proc2)
(console.log(((n)=>((isMultOf3)=>(isMultOf5)=>((b1)=>
(b2)=>b1(()=>b2)(()=>()=>(dfval)=>dfval()))(isMultOf3)
(isMultOf5)(()=>"FizzBuzz")(()=>isMultOf3(()=>"Fizz")
(()=>isMultOf5(()=>"Buzz")(()=>((n)=>n((x)=>x+1)(0))
(n)))))(((n)=>n(()=>()=>(dfval)=>dfval())((dtval)=>
()=>dtval()))(((g)=>((h)=>g((n)=>h(h)(n)))((h)=>g((n)=>
h(h)(n))))((mod)=>(n1)=>(n2)=>((n1)=>(n2)=>((n)=>n(()=>
()=>(dfval)=>dfval())((dtval)=>()=>dtval()))(((n1)=>
(n2)=>n2((n)=>((pair)=>pair(()=>(cdr)=>cdr))(n((pair)=>
((car)=>(cdr)=>(selector)=>selector(car)(cdr))(((n)=>
(s)=>(z)=>s(n(s)(z)))(((pair)=>pair((car)=>()=>car))
(pair)))(((pair)=>pair((car)=>()=>car))(pair)))((
(car)=>(cdr)=>(selector)=>selector(car)(cdr))((s)=>
(z)=>z)((s)=>(z)=>z))))(n1))(((n)=>(s)=>(z)=>s(n(s)(z)))
(n1))(n2)))(n1)(n2)(()=>n1)(()=>mod(((n1)=>(n2)=>
n2((n)=>((pair)=>pair(()=>(cdr)=>cdr))(n((pair)=>
((car)=>(cdr)=>(selector)=>selector(car)(cdr))(((n)=>
(s)=>(z)=>s(n(s)(z)))(((pair)=>pair((car)=>()=>car))
(pair)))(((pair)=>pair((car)=>()=>car))(pair)))(((car)=>
(cdr)=>(selector)=>selector(car)(cdr))((s)=>(z)=>z)
((s)=>(z)=>z))))(n1))(n1)(n2))(n2)))(n)((s)=>(z)=>s(s(s(z))))))
(((n)=>n(()=>()=>(dfval)=>dfval())((dtval)=>()=>dtval()))
(((g)=>((h)=>g((n)=>h(h)(n)))((h)=>g((n)=>h(h)(n))))
((mod)=>(n1)=>(n2)=>((n1)=>(n2)=>((n)=>n(()=>()=>(dfval)=>dfval())
((dtval)=>()=>dtval()))(((n1)=>(n2)=>n2((n)=>((pair)=>
pair(()=>(cdr)=>cdr))(n((pair)=>((car)=>(cdr)=>(selector)=>
selector(car)(cdr))(((n)=>(s)=>(z)=>s(n(s)(z)))(((pair)=>
pair((car)=>()=>car))(pair)))(((pair)=>pair((car)=>()=>car))
(pair)))(((car)=>(cdr)=>(selector)=>selector(car)(cdr))
((s)=>(z)=>z)((s)=>(z)=>z))))(n1))(((n)=>(s)=>(z)=>
s(n(s)(z)))(n1))(n2)))(n1)(n2)(()=>n1)(()=>mod(((n1)=>
(n2)=>n2((n)=>((pair)=>pair(()=>(cdr)=>cdr))(n((pair)=>
((car)=>(cdr)=>(selector)=>selector(car)(cdr))(((n)=>
(s)=>(z)=>s(n(s)(z)))(((pair)=>pair((car)=>()=>car))
(pair)))(((pair)=>pair((car)=>()=>car))(pair)))(((car)=>
(cdr)=>(selector)=>selector(car)(cdr))((s)=>(z)=>z)((s)=>
(z)=>z))))(n1))(n1)(n2))(n2)))(n)((s)=>(z)=>s(s(s(s(s(z)))))))))
(n)))(((n)=>(s)=>(z)=>s(n(s)(z)))(n)))((s)=>(z)=>s(z)))
(((n1)=>(n2)=>n2(n1))((s)=>(z)=>s(s(s(s(z)))))((s)=>(z)=>s(s(s(s(z))))))やばいっすね
コイツは実際に動作するのですが(暇な方はブラウザのJavaScriptコンソールなどにコピペしてみてください)、2,234文字あるので1つのツイートにはおさまりません。
Zコンビネータは必要か?
さきほどのコードでも、いろいろと細かい短縮のテクニックは思いつきます。
しかしもっと大きなところで、Zコンビネータがムダではないかと考えました。
聞きかじった程度なのですが、計算複雑性理論の世界には原始再帰関数という概念があり、ざっくりいうとwhileループ(事前に回数がわかっていないループ、今回ではZコンビネータが相当)を使用せずに実現できる関数とのことです。
そして、なんと日常的に扱うほとんどの計算が原始再帰関数で実現できるらしいです。
Wikipediaくんによると、
数論が扱う関数の多くや、実数を値とする関数の近似は原始再帰的であり、加法、除法、階乗、指数、n 番目の素数を求める関数などがある (Brainerd and Landweber, 1974年)。実際、原始再帰的でない関数を考案するのは難しい
とあり、じゃあ今回のFizzBuzzも原始再帰関数でいけるんじゃない?と考えました。
今回Zコンビネータを使用しているのはmodの計算なので、そこのwhileループが不要なのでは……?とひとりでもくもく悩んでいたのですが、
よく見たら同じページに不要って書かれてました。
原始再帰関数の例
- 剰余 (a, b): a が b で割り切れない場合の余り
やっぱりなぁと思いつつ、では実際にどうやって実装しようかと思っていたら、Recursion-free modular arithmetic in the lambda-calculusという、とても都合の良い論文が昨年に発表されてました。
論文をざっくり読んだ感じだと、
- 既存のチャーチ数によるあまりの計算には不動点コンビネータが必要であり、計算量も多くなりがちだ。
- そこで、モジュラー算術のための新しいエンコーディング方式を提案し、計算量も抑えられることを示す。
- また、中国剰余定理を利用することで、さらに計算量が削減されることも示す。
3の成果まで取り入れるとプログラムが長くなってしまいそうだったので、今回は2の成果だけ参考にさせていただきます。
モジュラー算術
Mod 3の世界における自然数とsucc、isZeroを以下のように定義します。
// 0は、3つの引数を受け取って、0番目の引数を返す関数
const _zeroMod3 = (a0) => (a1) => (a2) => a0;
// 1は、3つの引数を受け取って、1番目の引数を返す関数
const _oneMod3 = (a0) => (a1) => (a2) => a1;
// 2は、3つの引数を受け取って、2番目の引数を返す関数
const _twoMod3 = (a0) => (a1) => (a2) => a2;
// succはnを受け取って、「3つの変数を受け取って、それらをループするように並べ替えてnに適用する関数」を返す
const _succMod3 = (n) => (a0) => (a1) => (a2) => n(a1)(a2)(a0);
// isZeroはnを受け取って、そのnの0番目の引数にだけ_trueを渡す
const _isZeroMod3 = (n) => n(_true)(_false)(_false);succで変数をループするようにぐるぐる入れ替えているところがポイントです。
これまでのチャーチ数をMod 3の世界の数に変換するのは、チャーチ数のzをzeroMod3、sをsuccMod3として適用してやれば良いので簡単です。
そして、isZeroMod3によって3で割り切れるかどうかの判定もできます、あとはこれまでと同じようにFizzBuzzと、それを表示するためのコードを書くだけです。3
// see: https://www.sciencedirect.com/science/article/pii/S0020019023000510
// basic boolean
const _true = (tval) => () => tval;
const _false = () => (fval) => fval;
const _and = (b1) => (b2) => b1(b2)(_false);
// modular arithmetic
const _zeroMod3 = (a0) => (a1) => (a2) => a0;
const _succMod3 = (n) => (a0) => (a1) => (a2) => n(a1)(a2)(a0);
const _isZeroMod3 = (n) => n(_true)(_false)(_false);
const _zeroMod5 = (a0) => (a1) => (a2) => (a3) => (a4) => a0;
const _succMod5 = (n) => (a0) => (a1) => (a2) => (a3) => (a4) =>
n(a1)(a2)(a3)(a4)(a0);
const _isZeroMod5 = (n) => n(_true)(_false)(_false)(_false)(_false);
// church arithmetic
const _churchToNumber = (n) => n((x) => x + 1)(0);
const _churchToMod3 = (n) => n(_succMod3)(_zeroMod3);
const _isMultOf3 = (n) => _isZeroMod3(_churchToMod3(n));
const _churchToMod5 = (n) => n(_succMod5)(_zeroMod5);
const _isMultOf5 = (n) => _isZeroMod5(_churchToMod5(n));
// main
const _fizzBuzz = (n) =>
(
(isMultOf3) => (isMultOf5) =>
_and(isMultOf3)(isMultOf5)(
// n % 15 === 0
"Fizz Buzz"
)(
// n % 15 !== 0
isMultOf3(
// n % 3 === 0
"Fizz"
)(
// n % 3 !== 0
isMultOf5(
// n % 5 === 0
"Buzz"
)(
// n % 5 !== 0
_churchToNumber(n)
)
)
)
)(
// nが3で割り切れるかを計算して、isMultOf3に渡す
_isMultOf3(n)
)(
// nが5で割り切れるかを計算して、isMultOf5に渡す
_isMultOf5(n)
);
const _one = (s) => (z) => s(z);
const _four = (s) => (z) => s(s(s(s(z))));
const _succ = (n) => (s) => (z) => s(n(s)(z));
const _exp = (n1) => (n2) => n2(n1);
const _seq = (proc1) => (proc2) => proc2;
const _printFizzBuzzList = (printNum) =>
printNum((n) => _seq(console.log(_fizzBuzz(n)))(_succ(n)))(_one);
// print fizz buzz list to 256 = 4 ^ 4
_printFizzBuzzList(_exp(_four)(_four));で、これも例によって変数を展開できます。
// prettier-ignore
((printNum)=>printNum((n)=>((proc1)=>(proc2)=>proc2)
(console.log(((n)=>((isMultOf3)=>(isMultOf5)=>((b1)=>
(b2)=>b1(b2)(()=>(fval)=>fval))(isMultOf3)(isMultOf5)
("FizzBuzz")(isMultOf3("Fizz")(isMultOf5("Buzz")(((n)=>
n((x)=>x+1)(0))(n)))))(((n)=>((n)=>n((tval)=>()=>tval)
(()=>(fval)=>fval)(()=>(fval)=>fval))(((n)=>n((n)=>
(a0)=>(a1)=>(a2)=>n(a1)(a2)(a0))((a0)=>(a1)=>(a2)=>
a0))(n)))(n))(((n)=>((n)=>n((tval)=>()=>tval)(()=>
(fval)=>fval)(()=>(fval)=>fval)(()=>(fval)=>fval)
(()=>(fval)=>fval))(((n)=>n((n)=>(a0)=>(a1)=>(a2)=>
(a3)=>(a4)=>n(a1)(a2)(a3)(a4)(a0))((a0)=>(a1)=>(a2)=>
(a3)=>(a4)=>a0))(n)))(n)))(n)))(((n)=>(s)=>(z)=>
s(n(s)(z)))(n)))((s)=>(z)=>s(z)))(((n1)=>(n2)=>n2(n1))
((s)=>(z)=>s(s(s(s(z)))))((s)=>(z)=>s(s(s(s(z))))))これは738文字で、さきほどの2,234文字に比べるとだいぶ短くなっていて可能性を感じます。
さらに短縮
モジュラー演算バージョンのコードを以下のような方法で、さらに短縮していきます。
変数名を短くする
// 短縮前
(printNum) => ...
// 短縮後
(n) => ...アロー関数の引数のカッコを省略する
// 短縮前
(n) => ...
// 短縮後
n => ...引数がない関数にも引数を付ける
// 短縮前
() => ...
// 短縮後
a => ...同じ項は変数にまとめる
// 短縮前
n(t => f => t)(t => f => f)(t => f => f)(t => f => f)(t => f => f)
// 短縮後
(t => f => n(t)(f)(f)(f)(f))(t => f => t)(t => f => f)関数を適用する
// 短縮前
((printNum) => printNum(n => ...))(num)
// 短縮後
num(n => ...)カリー化をやめる
// 短縮前
(a=>b=>c=>...)(a)(b)(c)
// 短縮後
((a,b,c)=>...)(a,b,c)完成!
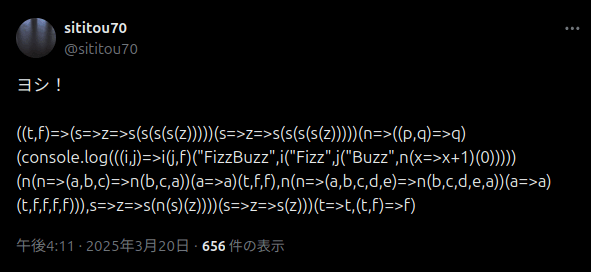
272文字になったのでツイートできました。
ヨシ!
— sititou70 (@sititou70) March 20, 2025
((t,f)=>(s=>z=>s(s(s(s(z)))))(s=>z=>s(s(s(s(z)))))(n=>((p,q)=>q)(console.log(((i,j)=>i(j,f)("FizzBuzz",i("Fizz",j("Buzz",n(x=>x+1)(0)))))(n(n=>(a,b,c)=>n(b,c,a))(a=>a)(t,f,f),n(n=>(a,b,c,d,e)=>n(b,c,d,e,a))(a=>a)(t,f,f,f,f))),s=>z=>s(n(s)(z))))(s=>z=>s(z)))(t=>t,(t,f)=>f)
なお、その後少しいじって258文字になったバージョンもあります。
// prettier-ignore
((t,f)=>(n=>n(n))(s=>z=>s(s(s(s(z)))))(n=>((p,q)=>q)
(console.log(((i,j)=>i(j,f)("FizzBuzz",i("Fizz",j("Buzz",
n(x=>x+1,0)))))(n(n=>(a,b,c)=>n(b,c,a),a=>a)(t,f,f),
n(n=>(a,b,c,d,e)=>n(b,c,d,e,a),a=>a)(t,f,f,f,f))),
(s,z)=>s(n(s,z))))((s,z)=>s(z)))(t=>t,(t,f)=>f)頑張ればまだ短縮できそうですが、キリがなさそうなのと、ツイートするという目標は達成したのでここでやめときます。
パフォーマンス実験
論文では、モジュラーバージョンの実装の方が計算の効率も良いと言っています。
ノーマルバージョンとモジュラーバージョンのFizzBuzzを、Node.jsでそれぞれ実行してみます。
$ time node normal.js > /dev/null
node normal.js > /dev/null 0.97s user 0.02s system 104% cpu 0.950 total
$ time node normal.js > /dev/null
node normal.js > /dev/null 0.97s user 0.04s system 103% cpu 0.977 total
$ time node normal.js > /dev/null
node normal.js > /dev/null 1.03s user 0.04s system 102% cpu 1.039 total
$ time node modulo.js > /dev/null
node modulo.js > /dev/null 0.07s user 0.02s system 105% cpu 0.090 total
$ time node modulo.js > /dev/null
node modulo.js > /dev/null 0.08s user 0.02s system 104% cpu 0.100 total
$ time node modulo.js > /dev/null
node modulo.js > /dev/null 0.08s user 0.02s system 104% cpu 0.097 totalまぁこれは純粋なあまりの計算だけではないので、あくまで参考程度という感じですが、10倍くらい早くなってます。
まとめ
ひさびさにラムダ計算で遊べて楽しかったです。
モジュラーバージョンのコードを手作業で短縮していた際、最初は「変数展開前のコードを手作業で短縮→変数展開」というフローでやっていたのですが、
途中から変数展開後のコードを直接いじれるようになってきて、住めば都って感じでした。
今回のコードはJavaScriptで書きましたが、その言語機能をほとんど使用していないので、他の言語へ比較的容易に移植できるはずです。
実際、なぜかSmalltalkに移植してくださった方がいて、なぜ?と思いました。
https://t.co/voFgBvYFpU Smalltalk でもヨシ!https://t.co/hbnD6A3U5u
— sumim (@sumim) March 21, 2025
(思ったよりあっさり動いたのでちょっと驚いている&感動しているのは内緒だw) https://t.co/5oJqAZ5vIF pic.twitter.com/9UJ3G7m0eu
お好みのプログラミング言語でラムダ計算すると楽しいのでおすすめです。
ありがとうございました。
- なにが?↩
λn f x. n (λg h. h (g f)) (λu. x) (λu. u)のこと。ラムダ計算のpredを理解するの解説が最高。↩- 不動点コンビネータを使わなくて良くなったので、条件判定部分の定義も簡単になっています。↩










