Gatsby製ブログで自然言語処理して関連記事を表示する
2020/06/12目次
Gatsby で作ったブログに関連記事機能がほしいと思い,記事間の関連度を算出する「gatsby-remark-related-posts」というGatsbyプラグインを作りました.
プラグインの使い方等は README に書いてあります.
ここでは,このプラグインを作るに至った背景や,内部のアルゴリズムについて書こうと思います.
背景
これは,当ブログを閲覧している人の行動フローです.
ご覧の通り, 記事へ直接アクセス → 離脱 という人が大半です.
それもそのはずで,これまでの私のブログには,各記事から他の記事へのリンクがありませんでした.
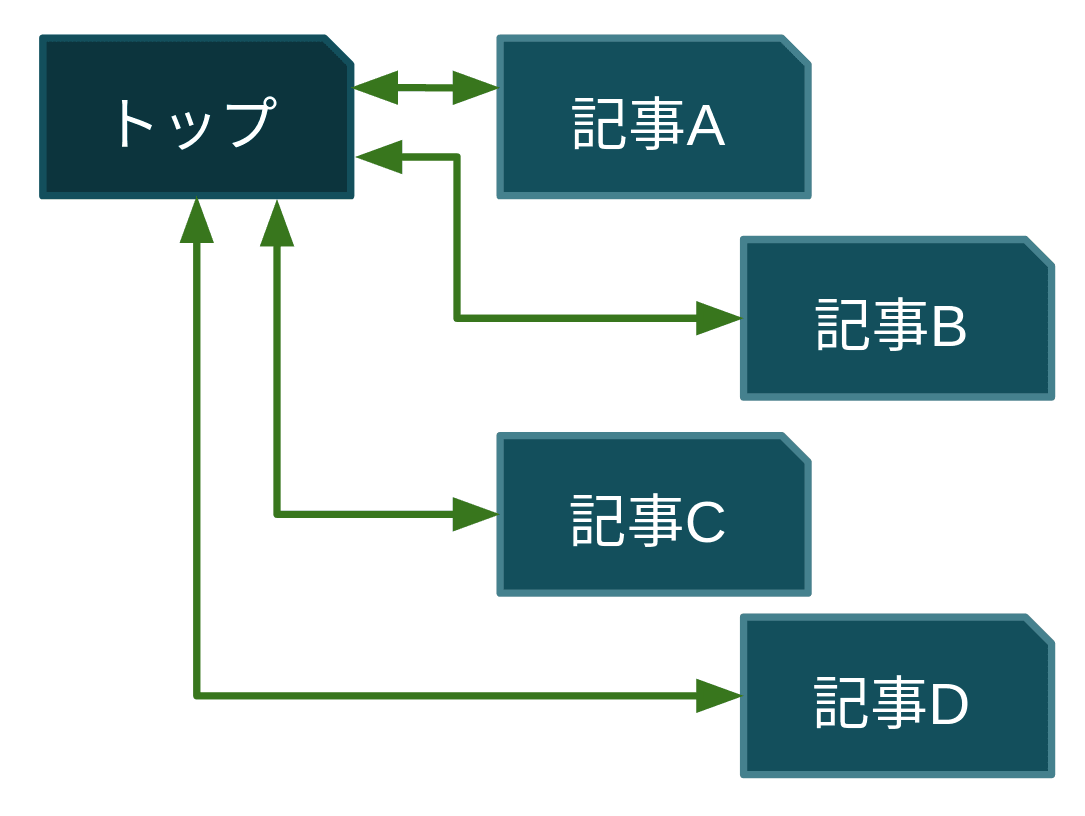
各記事には トップページへ戻る ためのリンクしかなかったため,離脱者が多いのは当然です.
そこで,各記事の最後に 関連記事へのリンク を設置することで,離脱率を軽減したいと考えました.
既存の手法
記事のカテゴリやタグを使う
- How to Build a Related Posts Component with Gatsby.js
- Gatsbyで作ったブログに関連記事を表示する
- Gatsbyブログに関連記事を表示するコンポーネントを追加する
- Related Blog Posts #2102
上記の手法では,いずれも記事のカテゴリやタグによって関連記事を表示しています.しかし,各記事のカテゴリやタグをうまく設定するためには,それなりのセンスと労力が必要です.
- タグの種類は適切な量か?
- 種類が少なすぎると記事をうまく分類できない
- 種類が多すぎるとタグ付けが難しくなる
- カテゴリはすべての記事をうまく分類できているか?
- 複数のカテゴリに属する記事は無いか
- 単語が表記ゆれしていないか?
- 開発,プログラミング,コーディング
- Node.js,Nodejs,nodejs,Node,js…
上記のようなことを気にしながらカテゴリやタグを保守していくのはしんどそうなので,今回は別のアプローチをとることにしました.
Hugoの関連記事機能を使う
Go言語製の静的サイトジェネレーターであるHugoには,デフォルトで関連記事を表示する機能があるらしいです.上記の手法では,その機能をGatsbyに移植しています.記事間の関連度を計算するアルゴリズムについて次のように述べています.
記事の全文を解析するようなガッツリした機能ではなく、 マークダウンのFront Matter(日付、タイトル、タグ、キーワード、カテゴリなど)をもとに関連度を測るシンプルな機能です。
先程の記事に比べると少し凝っていますが,やはり記事のカテゴリやタグ情報に依存しているようです.そのため,先程と同じ理由でパス.
tf-idfによるキーワード抽出
tf-idfを用いて,記事の全文からキーワードを抽出するというものです.キーワードが自動的に抽出できれば,あとは同じキーワードを持つ記事同士を関連記事とすれば良さそうです.
しかし,以下のような問題があったため,このプラグインは使えませんでした.
- 日本語に対応していない
- 複数記事に対応していない(?)
- READMEに「私達のコンテキストでは,if-idfにおける文書数は1だけです」的なことが書いてある
- (そもそも文書が1つしかないなら,idfを計算する意味とは…?)
アルゴリズムと実装
既存の手法では目的が達成できなさそうだったので,Gatsbyプラグインを自前で実装することにしました.
記事間関連度の算出アルゴリズム
保守や管理でラクをするためには,やはり記事全体を自然言語処理して記事間の関連度を算出するのが良さそうです.
言語処理に関してはまったくの素人なのですが(予防線),ざっくりと勉強してみました.その結果,基本に忠実に tf-idf と コサイン類似度 を用いることにしました.
日本語記事を分析するときの,具体的なアルゴリズムは次の通りです.
- 各記事を形態素解析して,単語をリストする
- ここで,単語のタイプが「一般」と「固有名詞」であるものだけをリストする
- 助詞や記号などが除かれるので,関連度の精度向上が見込める
- 各記事のすべての単語について,tf-idfを計算する
- 各記事で,tf-idfの高い上位n件の単語を取り出す
- nはデフォルトで30,プラグインのオプションで指定することもできる
- 取り出した単語をBoW(bag of words)して,記事の特徴ベクトルとする
- 記事間の関連度は,各記事の特徴ベクトルのコサイン類似度とする
プラグインの実装
特に難しいことはしていません.
TSを使ってGatsbyプラグインを書きました.文書やベクトルといった様々なデータ構造を取り扱うので,型によるサポートが大変ありがたかったです.
形態素解析には,kuromoji.jsを使いました.解析のための辞書もパッケージに付属しているので,形態素解析の環境がnpmだけで整ってしまいます!大変便利です.
アルゴリズムの精度
解析結果を見てみましょう
フォトリアリスティックな3DCGについて書いたBlenderで床を汚すの関連記事は次のようになりました.
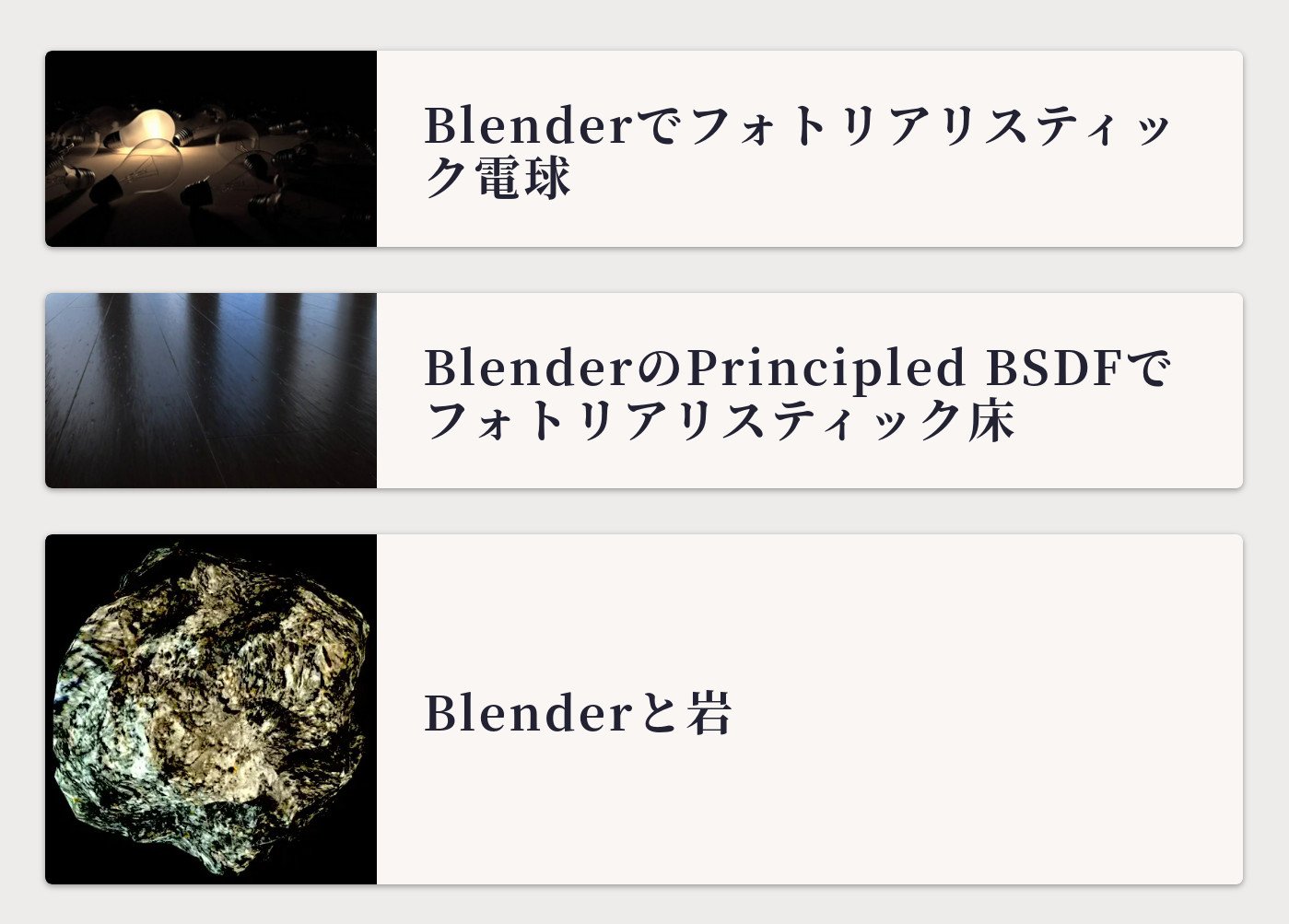
ちゃんと他のフォトリアリスティックに関する記事が上位に表示されています!
次に,IT企業の関係性について可視化したkurage - IT企業のフォロー関係を分析し、企業やエンジニアをランク付けするの関連記事は…

同じ可視化ネタの記事が,関連記事のトップに来ています.また,全体的に技術系の関連記事が表示されていていい感じです.
最後に,Linux KernelのMakefileについて書いたLinux kernelのMakefileを雰囲気で読んだ話の関連記事を見てみます.
Kernelビルドについて書いた姉妹記事が,関連にしっかりと表示されています.やったね.
まとめ
自然言語処理に関しては超絶素人の私ですが,基本に忠実に実装することで,そこそこの結果が得られました.こんな単純な方法でもそれなりに文書分類できる自然言語処理ってすげー.
本当は,Word2VecやDoc2Vec,SCDVなどの更に高度な手法も試してみたかったのですが,環境構築が面倒なのでやめてしまいました.精度を高めることも魅力なのですが,プラグインとして導入が簡単なことも重要ですよね.
「ブログに関連記事をざっくり表示したいけど,記事のメタデータを管理するのは面倒」という性格の私にとって,ちょうどいい規模感のプラグインが作れました.
よければみなさんも使ってください.









