自作の定理証明系を弱めてパラドックスを回避しよう
2025/07/29前回の記事では、依存型を持つ計算体系を論文をもとに写経し、その上で以下の総和の公式を証明しました。
しかし一方で、その体系が健全ではないことにも言及していました。
今回は
- 前回作成した体系が健全ではないことを確認します。ハーケンスのパラドックスを実装し、 を証明します。
- パラドックスを回避するために、型の階層構造を導入します。
- 階層構造が導入された体系で、総和の公式は証明できるが、パラドックスが構築できないことを確認します。
前回作成した体系が健全でないことを確認する
前回読んだ論文によれば
Finally, we should reiterate that the type system we have presented is unsound. As the kind of is itself , we can encode a variation of Russell’s paradox, known as Girard’s paradox [3]. This allows us to create an inhabitant of any type.
訳:最後に、我々が提示した型システムは健全ではないことを改めて強調しておくべきである。 のカインド自体が であるため、ラッセルのパラドックスの変種であるジラールのパラドックス[3]を符号化することができる。これにより、任意の型の要素を作成できるようになる。
出典:A tutorial implementation of a dependently typed lambda calculus
とのことです。
前回、
がマズそうと言ってたやつですね。
というわけで、ジラールのパラドックスについて調べますと、そのシンプルバージョンであるハーケンスのパラドックスというのがあり、RocqやAgdaで形式化もされているらしいです。シンプルなのは嬉しいですね。
で、さっそくRocqでの形式化を読んでみたのですが、残念ながら全く理解できませんでした。 いかがでしたか?
なんとなくの印象ですが、僕がやりたい事に対してリッチすぎる気がしました。
一方で、Agdaでの形式化の方は結構シンプルで、良さそうな雰囲気です。
ただ残念なことに、僕がAgdaをまったく読めないので、雰囲気しか語れません。
そこで、Geminiくんにお願いして、Agdaでの形式化をRocqのコードに変換してもらったのがsititou70/rocq-hurkens-paradoxです。Rocqにはデフォルトで型の階層構造がありますが、-type-in-typeオプションによってそれを無効化し、今回のパラドックスを構築できます。Geminiくんの出力は、1つの補題(lem3)の証明だけ僕が手で直しましたが、それ以外は一発で検査をパスしました。ほんと優秀ですね〜。
そうして完成した、読みやすく、かつシンプルな形式化により、ハーケンスのパラドックス自体も理解できるようになった わけありませんでした。 個別のコードの流れは分かるのですが、全体としての構成の意味や、その背景にある学問的な気持ちが何も分かりません。初学者なのにこう思うのは、「完全に理解した」の段階にすら行けてないということです。
試しに、ハーケンスの元論文である「A simplification of Girard's paradox」を覗いてみたのですが、宇宙語すぎて「へへ……」みたいな謎の笑いしか出ませんでした。純粋型システムであるSystem U(?)とかが使われていて、□とか△とかが楽しそうにしてるねぇという感じでした。
まぁ今回の目標は、パラドックスの理解ではなく退治なので、いったん良しとします。
形式化の要点を見てみます。冒頭では、以下のbot型を宣言しています。
Definition bot: Type := forall (A: Type), A.これは、「Aという型(命題)を受け取って、A型の値(命題の証明)を返す関数の型」という意味です。つまり、どんな命題でも、それを入れたら証明を返してくれる関数の型です。そんな関数が存在したら、その世界ではあらゆる命題が証明可能になるのでおかしいですよね。
そしていろいろあって、形式化の最後の方では、bot型の関数であるloopが得られています。
Definition loop: bot := lem2 lem3.loopに1 = 2を渡すと、その証明が実際に得られて、検査をパスしてしまいます。
Definition one_eq_two: 1 = 2 := loop (1 = 2).coqc -type-in-type hurkens.v
# エラーなし。1 = 2が証明された!これを前回作成した体系に移植したのがlambda-pi/test/paradox/hurkens.test.tsです。こちらでも、無事に(?) の証明をパスしました。
const oneEqTwoTerm: TermCheckable = makeApplyExpr(
loopAnn, // loopに
makeEqExpr([1, "=", 2], new Map()) // 1 = 2を渡す
);
// ...
// 1 = 2の証明を型検査するとパスする
test("check oneEqTwo", () => {
typeInferable(0)([])(oneEqTwoAnn);
});つまり、前回作成した体系は、パラドックスを構築できるほど強すぎるというわけです。
このような体系は、論理体系としては破綻していると言えます。
型の階層構造を導入してパラドックスを回避する
前回読んだ論文の続きによると
To fix this, the standard solution is to introduce an infinite hierarchy of types: the type of is , the type of is , and so forth.
訳:これを修正するための標準的な解決策は、型の無限階層を導入することである。つまり、 の型は 、 の型は 、というようになる。
出典:A tutorial implementation of a dependently typed lambda calculus
とのことです。
イメージとしては、
という制限を加えることで、総和の公式は証明できるが、パラドックスは構築できないように体系を弱めるという感じです。
Designing Dependently-Typed Programming Languagesの講義資料および講義動画を参考にして、型が階層構造を持つように型付け規則と評価規則を修正していきます。資料に情報がない部分については 勘で いい感じにしていきます。よろしくおねがいします。
型付け規則
が現れる規則だけが改造対象です。
一番興味深いのは、T-Star規則です。
に階層を表す添字が追加されました。あるレベルの は、その1つ上のレベルの に属するようになり、それが続いていきます。
T-Starと同じくらい重要なのが、T-Pi規則です。
が属する のレベルは、 と が属する のレベルの大きい方になります。
特に注目したいのは、依存関数自体の型のレベルが、引数 の型のレベルよりも常に大きくなるという性質です。
例えば、 として の値を受け取る依存関数があるとします。T-Piの結論より、 です。T-Piの1行目より を推論します。T-Star規則より となって、 になります。最終的な依存関数の型は となり、 が属する よりもレベルが大きくなるというわけです。
また細かいのですが、オリジナルのT-Pi規則とは違って、仮定の判別式が推論モードになっています。これは、 や の情報がもとの項に無いので仕方ないのですが、実装にじわじわ影響します。詳しくは後述します。
あとの規則はそこまで重要じゃないので畳んでおきます。
あとの規則
まず、 型と 型の型は です。
ここで、 という新しい記法を導入しました。これは「 であることを検査するが、レベルは任意である」という意味です。
これは独自の記法です。参考資料では検査ではなく推論を行ったうえで、レベルを無視して であることだけを確認するような感じになっていました。しかし、実装上の都合からこのようにしました。詳しくは後述します。
残りの規則に関しては、仮定部分に が現れるだけでオリジナルと同じです。
評価規則
特に面白くないのですが、いちおう完全のために載せておきます。
は評価しても です。
実装
まずはじめに、構文としてもStarにレベルを導入します。
export type TermInferable =
// ...
- | ["Star"]
+ | ["Star", number]これにより、プログラム中のStarと書いていた部分に、明示的にレベルの指定が必要になります。
Rocqでは Type と書く時にレベルを指定する必要はありませんが、それはRocqがよしなにレベルを推定してくれているからだそうです。
また、この機能に関連して、1つのプログラムを複数のレベルでインスタンス化するという機能(宇宙多相)もあるのだそうです。今回の体系には、もちろんそんな高度な機能は無いので、実際にハーケンスのパラドックスを持ってくる際には、似たようなコードを重複して書く必要がありました。ただ、総和の公式の証明ではそのような必要はなかったので、宇宙多相が無いことは、自然数に対する通常の証明を書く上ではそこまで問題にならないようでした。
Starの階層構造が導入できたら、あとは各規則を愚直にコードへ落とし込んでいくことになります。
ただ、T-Piの仮定の判別式については、もともと検査モードだったのが推論モードになっています。なので、依存関数の構文も同時に変更しないといけません。
export type TermInferable =
// ...
- | ["Pi", TermCheckable, TermCheckable]
+ | ["Pi", TermInferable, TermInferable]こうすると、検査器やユーティリティはもちろん、既存の証明(プログラム)コードも変更しないといけないので大変です。また、一部のユーテリティ(quote)の実装が非常に難しくなってしまい、別の方針のユーテリティを書くことになったりしました。なので、構文の変更というのはできるだけやりたくありません。
T-Pi以外にも、 が現れる規則はいくつかあるのですが、それらの規則では、T-Piのようにレベルを変数に束縛して結論で使いたいというわけではなく、単純に「何らかのレベルの であることを検査したい」だけのようでした。
そのような場合、講義資料では「型を推論して、その型が であることを確認する(レベルは無視する)」という動作でした。
今回の実装では、「型を検査するのはそのままで、検査器自体の動作を変更することで、その型が であることを確認する(レベルは無視する)」という動作にしました。また、そういう動作が必要なことを表す、検査器内部でだけ使用する特殊な構文 も定義しました。
どちらの方法で実装しても、検査の内容としては同等だと思います。講義資料の方が定義としてはきれいだと思いますが、今回は実装の簡単さと、元論文との対応を維持するために後者の方法を選択しました。
階層構造が導入された体系で、パラドックスが構築できないことを確認する
これは通常の(Type in Typeではない)Rocqでハーケンスのパラドックスを検査しているところです。
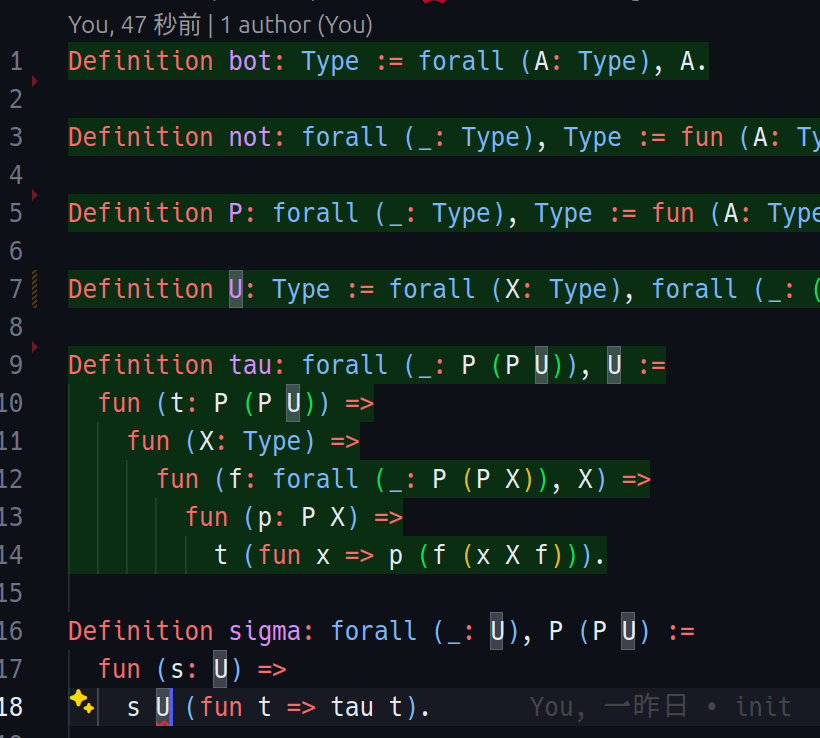
bot、not、P、U、tauというように、必要な項を次々定義していますが、sigmaという項は定義できていません。
なぜsigmaが定義できないのかというと、型の階層構造によって一種の自己適用が禁止されるからです。
sigmaの... fun (s: U) => s U ...という記述がエラーを起こしている部分です。s Uという適用があるので、sは関数です。Uはsの型なので依存関数型です。s Uという適用では、U自体がsに引数として渡されています(一種の自己適用)。
一般的に、引数を関数に渡すときは、実引数(渡そうとしている引数)に仮引数の型(関数側で宣言されている引数の型)が付くかが検査されます。例えば、 を 「 型の引数を持つ関数」に渡す場合、 が検査され、これはOKなので渡せます。
今回の場合を考えてみます。いま、Uを と仮においてみます。引数 のレベルが0なのも仮です。ここで、U自身を引数として渡そうとしているため、Uに「Uの引数の型」が付くか、つまり が検査されます。ここで、前述したT-Piの性質により、依存関数自体の型のレベル()が、引数の型のレベル()よりも大きくなることが要求されますが、 は成り立ちません。結局、引数 のレベルがどうであっても、s Uという適用は拒否され、パラドックスが回避されるというわけです。
詳しくはコード上のコメントに書きました。動作を理解するために、簡略化したUとsを定義して、実際に自己適用ができないのをテストしています。また、bot〜tauまでの定義が検査をパスするのも確認しました。
まとめ
というわけで、型の階層構造によって、ハーケンスのパラドックスが構築できなくなるのがわかりました。
一方、総和の公式の証明は、そのまま移植して検査をパスするのを確認できましたので、目標達成です。
ちなみに、階層構造を導入する前の前回の体系で、 の証明項を確認すべく評価してみると、
evalInferable(oneEqTwoAnn)([]);
// RangeError: Maximum call stack size exceededスタックを突き破ってエラーになってしまいました。実質的に無限ループが発生しているようです。
無限ループによってあらゆる命題が証明できてしまうというのは、TAPLにある「不動点コンビネータに型付けできるとすべての命題が証明可能になってしまう話」に似ているなと思いました。↑のリンクは、以前カワるガワるTAPLカタるヨるというイベントに呼んでいただいた際に発表した資料です。
不動点コンビネータはラッセルのパラドックスと関係しているという話もありますし、ここらへんの自己言及の親戚たちは、おそらく原理的には同じような仕組みを持っているんだろうな〜〜という気持ちになりました。
もちろん、今回の修正によって体系が健全になったとは言えないです。厳密にはちゃんと健全性を証明しないといけないし、けっこう勘でいろいろいじくったので、どこかおかしくしてしまった可能性は十分あります。
なので、間違いとかツッコミがあれば教えていただけると助かります。
ありがとうございました。








