ECMA-262を読んだ日
2022/06/10

お仕事でJavaScriptを書いています.sititou70です.
人生ではじめてECMA-262を読んだので,記念的日記を残したいと思います.
いきさつ
ある日のお仕事で,「ユーザーが入力した文字列の コードポイント数 を数えたい」という場面がありました.
さっそく「mdn string codepoint length」でググってみると,以下の情報が見つかりました.
lengthは文字数ではなくコードユニットの数を数えるため、文字数を知りたい場合はこのようなことをする必要があります。function getCharacterLength(str) { return [...str].length; }
な……なるほど???
getCharacterLengthを使うことで 「文字数」 がわかると言っています.しかし,ここでの 「文字数」 って?
ちょっとテストしてみます.
// 🤔 = 🤔(U+1F914)
getCharacterLength("🤔"); // 1
// が = か(U+304B) + ゙(U+3099)
getCharacterLength("が"); // 2
// 👨👩👧👦 = 👨(U+1F468) + ゼロ幅接合子(U+200D) + 👩(U+1F469) + (U+200D) + 👧(U+1F467) + (U+200D) + 👦(U+1F466)
getCharacterLength("👨👩👧👦"); // 7あ,なんかコードポイント数を返す っぽい
ですが,そのようにキッパリと言及されているわけではないので,多少モヤモヤしますね.もしかしたら,「コードポイントを数える っぽい 動作」なだけで,上記のテストではわからない例外があるのかもしれません.
MDNの本文には,これ以上の情報はなさそうです.しかし,「仕様書」というセクションにECMA-262へのリンクがありました.
良い機会なので,ECMA-262を雰囲気で読んでみましょう.
スプレッド構文を調べる
なにはともあれ,https://tc39.es/ecma262/ にアクセスします.こちらのHTMLファイルですが,なんと 6.5MBもある ので開くだけでなんだか一仕事終えた気になれます.
さて,どこから読んでいこうかとなるわけですが,私は「スプレッド構文」が内部でどのように処理されているのか?というところからよくわかっていませんでした.
ページを開くと,いきなり検索ボックスが設置されていますので,

「spread」と入力して雑に一番上の結果へ飛んでみました.
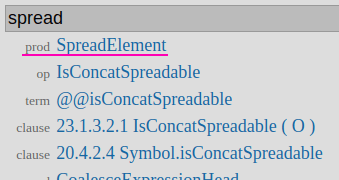
すると,

13.2.4 Array InitializerのSpreadElementにドンピシャ飛ばされました.魔法の検索ボックスかな?
13.2.4は以下のような構成になっています.
- 13.2.4 Array Initializer
- Syntax
- 13.2.4.1 Runtime Semantics: ArrayAccumulation
- 13.2.4.2 Runtime Semantics: Evaluation
なーるほど,配列の初期化に関する 文法と意味 を定義しているんですね.
ひとまずSyntax節を見てみますと
SpreadElement:
... AssignmentExpressionとあります.「...に続けてAssignmentExpressionを書く」と定義されていますので,今回はAssignmentExpressionの部分が文字列リテラルに相当するみたいです.
ホントかどうか,AssignmentExpression の定義を追って文字列リテラルが出てくるのを確かめてみます
AssignmentExpression:
ConditionalExpression
...その他の定義...
ConditionalExpression:
ShortCircuitExpression
...その他の定義...
ShortCircuitExpression:
LogicalORExpression
...その他の定義...
LogicalORExpression:
LogicalANDExpression
...その他の定義...
LogicalANDExpression:
BitwiseORExpression
...その他の定義...
BitwiseORExpression:
BitwiseXORExpression
...その他の定義...
BitwiseXORExpression:
BitwiseANDExpression
...その他の定義...
BitwiseANDExpression:
EqualityExpression
...その他の定義...
EqualityExpression:
RelationalExpression
...その他の定義...
RelationalExpression:
ShiftExpression
...その他の定義...
ShiftExpression:
AdditiveExpression
...その他の定義...
AdditiveExpression:
MultiplicativeExpression
...その他の定義...
MultiplicativeExpression:
ExponentiationExpression
...その他の定義...
ExponentiationExpression:
UnaryExpression
...その他の定義...
UnaryExpression:
UpdateExpression
...その他の定義...
UpdateExpression:
LeftHandSideExpression
...その他の定義...
LeftHandSideExpression:
NewExpression
CallExpression
OptionalExpression
...その他の定義...
OptionalExpression:
MemberExpression
...その他の定義...
MemberExpression:
PrimaryExpression
...その他の定義...
PrimaryExpression:
this
IdentifierReference
Literal
...その他の定義...
Literal:
NullLiteral
BooleanLiteral
NumericLiteral
StringLiteral(あった)
StringLiteral:
" DoubleStringCharactersopt "
' SingleStringCharactersopt '長っげ!
遭難するかと思った
次に,13.2.4.1 Runtime Semantics: ArrayAccumulation節を見てみます.

SpreadElementの意味は,このような独特の表現で定義されていました.
ちょっと分かりづらいので,JavaScript風に書き直して読んでみます.
let array; // 現在初期化している配列
let nextIndex; // 次に値を追加すべきインデックス
function SpreadElementのセマンティクス(AssignmentExpression) {
// 1. Let spreadRef be the result of evaluating AssignmentExpression.
// 今回の評価結果は文字列リテラルそのもの
let spreadRef = `AssignmentExpressionを評価した結果`;
// 2. Let spreadObj be ? GetValue(spreadRef).
// GetValue: リファレンスを解決して値を得る
// 今回の場合は,文字列リテラル(をGetしたCompletion Record)がspreadObjに入る
let spreadObj = GetValue(spreadRef);
// 3. Let iteratorRecord be ? GetIterator(spreadObj).
// GetIterator: イテレータレコードを得る
// イテレータレコードとは,{ [[Iterator]]: iterator, [[NextMethod]]: nextMethod, [[Done]]: false } みたいなやつ
let iteratorRecord = GetIterator(spreadObj);
// 4. Repeat,
while (true) {
// a. Let next be ? IteratorStep(iteratorRecord).
// IteratorStep: イテレータから次の結果を得る.イテレータが完了していればfalseを得る
// 結果とは,{value: value, done: boolean} みたいなやつ
let next = IteratorStep(iteratorRecord);
// b. If next is false, return nextIndex.
// イテレータが完了していればループを終了する
if (!next) return nextIndex;
// c. Let nextValue be ? IteratorValue(next).
// IteratorValue: 結果から値を得る.実質valueプロパティを参照しているだけ
let nextValue = IteratorValue(next);
// d. Perform ! CreateDataPropertyOrThrow(array, ! ToString(𝔽(nextIndex)), nextValue).
// CreateDataPropertyOrThrow: オブジェクトにプロパティを生やす
// 今回は,arrayのnextIndex番地にnextValueの値を設定している
// 𝔽: 仕様書内で扱っているような抽象的な数値を,ECMAScriptのNumberの範囲へ変換する
// ToString: numberやbooleanなど,様々なタイプの値を文字列に変換する
CreateDataPropertyOrThrow(array, ToString(𝔽(nextIndex)).Value, nextValue);
// e. Set nextIndex to nextIndex + 1.
nextIndex = nextIndex + 1;
}
}更に詳細な説明
// 補足:'?'ショートハンド(ReturnIfAbrupt)は,前の操作結果がabrupt completionであるときそれをreturnする.
// 本記事では簡単のため省略
//// abrupt completion: TypeフィールドがnormalでないCompletion Record
//// Completion Record: 各セマンティクスの実行結果を表すような,仕様書の中でのみ使われるレコード型
//// Typeフィールド: 実行がどのように完了したかを表す.値は次のうちのどれか: normal, break, continue, return, throw
//// see: https://tc39.es/ecma262/#sec-completion-record-specification-type
// 補足:'!'ショートハンドは,前の操作結果がabrupt completionでないことを前提として,その値を即座に取り出す
// 失敗しない操作を簡単に扱うためにあるっぽい
// see: https://tc39.es/ecma262/#sec-completion-record-specification-type
// Vのリファレンスを解決して値を取り出してくれる抽象操作……らしい(よくわかってない)
// see: https://qiita.com/uhyo/items/39750a5359629b3fee05
//// 抽象操作: 仕様書の中でのみ使われる手続きのようなもの
function GetValue(V) {
// ReturnIfAbrupt(V).
if (V.Type !== "normal") return Completion(spreadObj);
// 2. If V is not a Reference Record, return V.
if (`VがReference Recordタイプではない`) return V; // 今回はVがリファレンスでないので,ここで返るっぽい
// 3. If IsUnresolvableReference(V) is true, throw a ReferenceError exception.
// 4. If IsPropertyReference(V) is true, then
// a. Let baseObj be ? ToObject(V.[[Base]]).
// b. If IsPrivateReference(V) is true, then
// i. Return ? PrivateGet(baseObj, V.[[ReferencedName]]).
// c. Return ? baseObj.[[Get]](V.[[ReferencedName]], GetThisValue(V)).
// 5. Else,
// a. Let base be V.[[Base]].
// b. Assert: base is an Environment Record.
// c. Return ? base.GetBindingValue(V.[[ReferencedName]], V.[[Strict]]) (see 9.1).
}
// objからイテレータレコードを得る
function GetIterator(obj, hint, method) {
// If hint is not present, set hint to sync.
if (hint === undefined) hint = "sync"; // 今回はhintを指定していないのでhintは"syncになる"
// 2. If method is not present, then
if (method === undefined) {
if (hint === "async") {
// a. If hint is async, then
// i. Set method to ? GetMethod(obj, @@asyncIterator).
// ii. If method is undefined, then
// 1. Let syncMethod be ? GetMethod(obj, @@iterator).
// 2. Let syncIteratorRecord be ? GetIterator(obj, sync, syncMethod).
// 3. Return CreateAsyncFromSyncIterator(syncIteratorRecord).
} else {
// 今回はこちらに入る
// b. Otherwise, set method to ? GetMethod(obj, @@iterator).
let method = GetMethod(obj, "@@iterator");
}
}
// 3. Let iterator be ? Call(method, obj).
let iterator = Call(method, obj); // クロージャからイテレータが作成されて返る(後述)
// 4. If Type(iterator) is not Object, throw a TypeError exception.
if (typeof iterator !== "Object") throw "TypeError exception";
// 5. Let nextMethod be ? GetV(iterator, "next").
let nextMethod = GetV(iterator, "next");
// 6. Let iteratorRecord be the Iterator Record { [[Iterator]]: iterator, [[NextMethod]]: nextMethod, [[Done]]: false }.
let iteratorRecord = {
Iterator: iterator,
NextMethod: nextMethod,
Done: false,
};
// 7. Return iteratorRecord.
return iteratorRecord;
}
// VからメソッドPを得る
function GetMethod(V, P) {
// 1. Let func be ? GetV(V, P).
let func = GetV(V, P); // 今回は"@@iterator"プロパティにある関数オブジェクトが得られるはず
// 2. If func is either undefined or null, return undefined.
if (func === undefined || func === null) return undefined; // 今回は当てはまらない
// 3. If IsCallable(func) is false, throw a TypeError exception.
if (!IsCallable(func)) throw "TypeError exception"; // "@@iterator"関数が呼び出し可能なので今回は該当しない
// 4. Return func.
return func;
}
// VからプロパティPの値を得る
function GetV(V, P) {
// 1. Let O be ? ToObject(V).
let O = ToObject(V); // Oには文字列が入るっぽい
// 2. Return ? O.[[Get]](P, V).
// String Exotic Objectsには[[Get]]の定義はなかったからOrdinary Objectの[[Get]]が適用されるはず
// see: https://tc39.es/ecma262/#sec-ordinary-object-internal-methods-and-internal-slots-get-p-receiver
//// Ordinary Object: 普通のオブジェクト
//// Exotic Object: 普通のオブジェクトを拡張・継承して定義される特別なオブジェクト.ArrayとかStringとか.
return O.Get(P, V);
}
// argumentをオブジェクトに変換する
function ToObject(argument) {
// 今回はargumentの値はStringリテラル
switch (typeof argument.Value) {
case "Undefined": // Throw a TypeError exception.
case "Null": // Throw a TypeError exception.
case "Boolean": // Return a new Boolean object whose [[BooleanData]] internal slot is set to argument. See 20.3 for a description of Boolean objects.
case "Number": // Return a new Number object whose [[NumberData]] internal slot is set to argument. See 21.1 for a description of Number objects.
case "String":
// ここに入る
// Return a new String object whose [[StringData]] internal slot is set to argument. See 22.1 for a description of String objects.
// [[StringData]]内部スロットは,Stringのデータ(UFT-16のデータ?)を保持するらしい…….よくわかっていないけど↓みたいなこと?
return new String(argument.Value);
case "Symbol": // Return a new Symbol object whose [[SymbolData]] internal slot is set to argument. See 20.4 for a description of Symbol objects.
case "BigInt": // Return a new BigInt object whose [[BigIntData]] internal slot is set to argument. See 21.2 for a description of BigInt objects.
case "Object": // Return argument.
}
}
Object.prototype.Get = function (P, Receiver) {
let O = this;
return OrdinaryGet(O, P, Receiver);
};
// この抽象操作以降の操作は深く追わないことにします
function OrdinaryGet(O, P, Receiver) {
// 1. Let desc be ? O.[[GetOwnProperty]](P).
let desc = O.GetOwnProperty(P); // Oの"@@iterator"プロパティをGetする
if (desc === undefined) {
// 自分がPを持っていなかったら親へプロトタイプチェーンをたどる操作.ここではStringが"@@iterator"を持っているので該当しない
// 2. If desc is undefined, then
// a. Let parent be ? O.[[GetPrototypeOf]]().
// b. If parent is null, return undefined.
// c. Return ? parent.[[Get]](P, Receiver).
}
// 以下の処理では,Getしたい対象のものがdata propertyなのか,accessor propertyなのかによって処理を分けている
// data property: ふつうの値
// accessor property: アクセサ関数を通してGetすべき値.Getterとか?
//// 試しにgetterについてgetOwnPropertyDescriptorしたらget属性が得られたからたぶんそう
// see: https://tc39.es/ecma262/#sec-object-type
// 3. If IsDataDescriptor(desc) is true, return desc.[[Value]].
// descがdata propertyならそのValue(そのものの値)を返す.
// "@@iterator"は普通の関数オブジェクトでGetterではないからここで返るはず
if (IsDataDescriptor(desc)) return desc.Value;
// 以下,descがaccessor propertyならそれを呼び出して得た値を返している
// 4. Assert: IsAccessorDescriptor(desc) is true.
// 5. Let getter be desc.[[Get]].
// 6. If getter is undefined, return undefined.
// 7. Return ? Call(getter, Receiver).
}
// argumentが呼び出し可能か判定する
function IsCallable(argument) {
// 1. If Type(argument) is not Object, return false.
if (typeof argument !== "Object") return false;
// 2. If argument has a [[Call]] internal method, return true.
if (`argumentが[[Call]]内部メソッドを持っている`) return true;
// 3. Return false.
return false;
}
// 内部メソッドを呼び出すために使用される
function Call(F, V, argumentsList) {
// 1. If argumentsList is not present, set argumentsList to a new empty List.
if (argumentsList === undefined) argumentsList = [];
// 2. If IsCallable(F) is false, throw a TypeError exception.
if (!IsCallable(F)) throw "TypeError exception";
// 3. Return ? F.[[Call]](V, argumentsList).
// Fが呼び出し可能だとわかったので,実際に呼び出しを行って結果を返す.
return F.Call(V, argumentsList);
}
// イテレータの次の結果を得る
function IteratorStep(iteratorRecord) {
// 1. Let result be ? IteratorNext(iteratorRecord).
let result = IteratorNext(iteratorRecord); // 値を得る
// 2. Let done be ? IteratorComplete(result).
let done = IteratorComplete(result); // 完了状態を得る
// 3. If done is true, return false.
if (done) return false; // 既にイテレーターが完了していばfalseを返す
// 4. Return result.
return result;
}
// イテレーターのNextを実行して結果を返す
function IteratorNext(iteratorRecord, value) {
// 1. If value is not present, then
let result;
if (value === undefined) {
// 今回の呼び出しでは多くの場合こちら
// a. Let result be ? Call(iteratorRecord.[[NextMethod]], iteratorRecord.[[Iterator]]).
let result = Call(iteratorRecord.NextMethod, iteratorRecord.Iterator); // NextMethodをIteratorで実行し,次の値を得る
} else {
// 2. Else,
// a. Let result be ? Call(iteratorRecord.[[NextMethod]], iteratorRecord.[[Iterator]], « value »).
}
// 3. If Type(result) is not Object, throw a TypeError exception.
if (typeof argument !== "Object") throw "TypeError exception";
// 4. Return result.
return result;
}
// イテレーターが完了しているか判定する
function IteratorComplete(iterResult) {
// 1. Return ToBoolean(? Get(iterResult, "done")).
return Boolean(Get(iterResult, "done")); // iterResultオブジェクトのdoneプロパティを得て,Booleanに変換して返す
}
// イテレータの結果から値を得る
function IteratorValue(iterResult) {
// 1. Return ? Get(iterResult, "value").
return Get(iterResult, "value");
}
function Get(O, P) {
// 1. Return ? O.[[Get]](P, O).
// Oの種類によって適切な[[Get]]が呼ばれる.
// 例えば,OがOrdinary Objectの場合は上述したObject.prototype.Getが呼ばれるはず
return O.Get(P, o);
}
// オブジェクトOにプロパティPを生やしてVをセットする.無理そうなら例外を投げる
function CreateDataPropertyOrThrow(O, P, V) {
// 1. Let success be ? CreateDataProperty(O, P, V).
let success = CreateDataProperty(O, P, V);
// 2. If success is false, throw a TypeError exception.
if (!success) throw "TypeError exception";
// 3. Return success.
return success;
}
function CreateDataProperty(O, P, V) {
// 1. Let newDesc be the PropertyDescriptor { [[Value]]: V, [[Writable]]: true, [[Enumerable]]: true, [[Configurable]]: true }.
// 新しいPropertyDescriptorを作成する.これはdata property用のDescriptor
let newDesc = {
Value: V,
Writable: true,
Enumerable: true,
Configurable: true,
};
// 2. Return ? O.[[DefineOwnProperty]](P, newDesc).
return O.DefineOwnProperty(P, newDesc); // プロパティを登録.詳細は割愛
}
// completionRecordがCompletion Recordタイプであることを強調する目的.
// アサーションに失敗した時になにかしたいわけではない.
function Completion(completionRecord) {
// 1. Assert: completionRecord is a Completion Record.
assert(`completionRecordがCompletion Recordタイプであること`);
// 2. Return completionRecord.
return completionRecord;
}書き直してみて,かえって分かりづらくなっている気がしなくもないです.
ともかくAssignmentExpressionのイテレータを得て,その結果を順に配列へ追加しているわけですねー
String.prototype [ @@iterator ] ( )
では,文字列からはどのようなイテレータが得られるのでしょうか.
というわけで,これまた検索ボックスに「string iterator」と入力すると,22.1.3.34 String.prototype [ @@iterator ] ( )がしっかりとヒットしました.ホント優秀ですねこれ.
![22.1.3.34 String.prototype [ @@iterator ] ( )のスクリーンショット](/static/8aafba2c8f29179e3443a8f4d2dfbe36/e5cab/string_iterator.png)
冒頭を読んでみますと,
When the @@iterator method is called it returns an Iterator object (27.1.1.2) that iterates over the code points of a String value, returning each code point as a String value.
訳:@@iteratorが呼ばれると,文字列全体の各コードポイントを1つずつ反復するようなイテレータを返します
とありますので,期待通りの挙動をしそうですね!
念の為ステップも読んでみます
String.prototype.iterator = function () {
// 1. Let O be ? RequireObjectCoercible(this value).
// RequireObjectCoercible: 引数がオブジェクトに変換できるなら引数をそのまま返す.変換できないなら例外を投げる
// 今回の場合thisはStringなのでthisがそのまま返る
let O = RequireObjectCoercible(this);
// 2. Let s be ? ToString(O).
// ToString: booleanやnumberなど,様々なタイプの値を文字列に変換する
// 今回の場合Oは文字列なのでそのまま返る
let s = ToString(O);
// 3. Let closure be a new Abstract Closure with no parameters that captures s and performs the following steps when called:
let closure = function () {
// ここがイテレータロジックの本体です.
// a. Let position be 0.
let position = 0;
// b. Let len be the length of s.
let len = s.length;
// c. Repeat, while position < len,
while (position < len) {
// i. Let cp be CodePointAt(s, position).
// CodePointAt: sをUTF-16バイトシーケンスとして解釈し,そのpositionから始まる単一のコードポイントに関する情報を返す
// 注意: String.prototypeにも同じ名前のメソッドがあるが,こちらは抽象操作
// 返される情報:
//// [[CodePoint]]: コードポイントの値
//// [[CodeUnitCount]]: コードユニットの個数.サロゲートペアの場合は2,それ以外は1
//// [[IsUnpairedSurrogate]]: サロゲートペアの組み合わせがおかしい場合にtrue,それ以外はfalse
let cp = CodePointAt(s, position);
// ii. Let nextIndex be position + cp.[[CodeUnitCount]].
// サロゲートペアの場合はnextIndexが2進む
let nextIndex = position + cp.CodeUnitCount;
// iii. Let resultString be the substring of s from position to nextIndex.
// サロゲートペアも1文字として,現在の文字を取り出す
let resultString = s.slice(position, nextIndex + 1);
// iv. Set position to nextIndex.
position = nextIndex;
// v. Perform ? GeneratorYield(CreateIterResultObject(resultString, false)).
// CreateIterResultObject: (value, done)を受け取って{value: value, done: done}というオブジェクトを作る
// GeneratorYield: イテレータから値を返す.詳細は割愛
GeneratorYield(CreateIterResultObject(resultString, false));
}
// d. Return undefined.
return undefined;
};
// 4. Return CreateIteratorFromClosure(closure, "%StringIteratorPrototype%", %StringIteratorPrototype%).
// CreateIteratorFromClosure: ジェネレータを作成する.引数の意味は以下の通り.詳細は割愛
//// closure: 引数を取らない抽象クロージャ.イテレータロジックの本体
//// generatorBrand: いろいろなジェネレータを区別するための内部スロット?よくわかっていない.
////// see: https://tc39.es/ecma262/#sec-properties-of-asyncgenerator-intances
//// generatorPrototype: イテレータが登録される場所,プロトタイプ
return CreateIteratorFromClosure(
closure,
"%StringIteratorPrototype%",
String.prototype.Iterator
);
};
function CodePointAt(string, position) {
// 1. Let size be the length of string.
let size = string.length;
// 2. Assert: position ≥ 0 and position < size.
// 事前条件を強調する目的.アサーションが失敗したときになにかしたいわけではない
assert(position >= 0 && position < size);
// 3. Let first be the code unit at index position within string.
// positionの最初の文字を得る
let first = string[position];
// 4. Let cp be the code point whose numeric value is that of first.
// positionの最初の文字の数値を得る
let cp = string.charCodeAt(position);
// 5. If first is not a leading surrogate or trailing surrogate, then
if (`firstが上位サロゲートでない` || `firstが下位サロゲートでない`) {
// つまりBMPの文字.サロゲート関係ない
// a. Return the Record { [[CodePoint]]: cp, [[CodeUnitCount]]: 1, [[IsUnpairedSurrogate]]: false }.
return { CodePoint: cp, CodeUnitCount: 1, IsUnpairedSurrogate: false };
}
// 6. If first is a trailing surrogate or position + 1 = size, then
if (`firstが下位サロゲート` || position + 1 === size) {
// positionが下位サロゲートを指してしまっている,または文字列が上位サロゲートで中途半端に終わっている
// a. Return the Record { [[CodePoint]]: cp, [[CodeUnitCount]]: 1, [[IsUnpairedSurrogate]]: true }.
// UnpairedSurrogateだ!
return { CodePoint: cp, CodeUnitCount: 1, IsUnpairedSurrogate: true };
}
// ここまで来ると,
//// 1. 今回扱いたい文字はBMPでない
//// 2. firstの「次の文字」がある(position + 1 !== sizeである)
// したがって,次の文字は下位サロゲートに違いない (a)
// 7. Let second be the code unit at index position + 1 within string.
let second = string[position + 1];
// 8. If second is not a trailing surrogate, then
if (`secondが下位サロゲートでない`) {
// (a) なのに,secondが下位サロゲートでない!文字列がおかしいのでUnpairedSurrogateだ!
// a. Return the Record { [[CodePoint]]: cp, [[CodeUnitCount]]: 1, [[IsUnpairedSurrogate]]: true }.
return { CodePoint: cp, CodeUnitCount: 1, IsUnpairedSurrogate: true };
}
// ここまで来て,ようやく上位サロゲートと下位サロゲートが揃った
// 9. Set cp to UTF16SurrogatePairToCodePoint(first, second).
// UTF16SurrogatePairToCodePoint: 上位・下位サロゲートからコードポイントを得る
cp = UTF16SurrogatePairToCodePoint(first, second);
// 10. Return the Record { [[CodePoint]]: cp, [[CodeUnitCount]]: 2, [[IsUnpairedSurrogate]]: false }.
return { CodePoint: cp, CodeUnitCount: 2, IsUnpairedSurrogate: false };
}
function UTF16SurrogatePairToCodePoint(lead, trail) {
// 1. Assert: lead is a leading surrogate and trail is a trailing surrogate.
assert(`leadは上位サロゲート` && `trailは下位サロゲート`);
// 2. Let cp be (lead - 0xD800) × 0x400 + (trail - 0xDC00) + 0x10000.
let cp = (lead - 0xd800) * 0x400 + (trail - 0xdc00) + 0x10000;
// 3. Return the code point cp.
return cp;
}前節でだいぶ疲れたので深追いはしていませんが,文字列のイテレータが思ったとおりの挙動であることを確かめられました!
まとめ
[..."文字列"].lengthによってコードポイント数がわかるのか,その詳細な挙動が知りたくてECMA-262を読みました.その結果,所望の結果が得られることを確かめられました.
ところで後になって調べてみると,今回の結論を書いているブログをいくつも見つけました 🙃
- JavaScriptにおける文字コードと「文字数」の数え方 | blog.jxck.io
- 文字列とUnicode · JavaScript Primer #jsprimer
- JavaScript: 文字数を正確にカウントするには?
ECMA-262より分かりやすい!😇
最初からよくググって,こっちを見たほうが早かったですね.
ともあれ,仕様書を読むことで周辺知識の理解が深まった気がします.
ECMA-262初心者なので,間違いがあればご指摘ください.
ありがとうございました









